Data Labeling is Dead
Written by John Singleton Co-founder @ Watchful
tl;dr
- Data Labeling as we know it today is dead. Well…at least dying
- Tools and solutions have evolved over time to make the process of distilling and applying human-centric knowledge to data more efficient
- Transformers and the subsequent Large Language Model (LLM) revolution have fundamentally shifted the economics of knowledge management and access
- Labeling Companies as we know it today need to evolve or die - the workflows and pain points are shifting due to the proliferation and continued improvement of LLMs
- At Watchful - we are embracing the change and building a suite of tools and features to service the new, data-centric AI workflow of today
November 30th, 2023 - The Day Data Labeling Died. Ok ok…maybe quite not D.O.A., but the release of ChatGPT and the viral proliferation of foundation models amongst both technical and non-technical roles marks the beginning of the end for what we have come to understand as a required, resource intensive part of the model development lifecycle. The idea that developing performant machine learning models requires an army of humans (or a small team of already overworked data professionals) manually labeling large amounts of data for supervised learning tasks is quickly diminishing.
The ecosystem of data labeling services and tools is going through a defining moment — evolve or die. Let’s see how we got here, what exactly changed with the release of ChatGPT, and see how we are building for the modern, data-centric model development workflow of the future.
How Did We Get Here?
First, let’s start by defining a data label…
As Defined by ChatGPT:
A data label in machine learning refers to the "ground truth" or known outcome associated with a particular data point or sample. Labels are used to supervise the learning process of algorithms in a category of techniques known as supervised learning. They guide the algorithm to learn the correct function that maps input data (features) to output data (labels).
For instance, if we train a machine learning model to classify emails into "spam" or "not spam", the labels would be the actual classification of each email in our training dataset. These labels then train the model, enabling it to generalize from this data and correctly classify new, unseen emails.
Put even more simply, a label is just the distillation of human-centric concepts or knowledge to arbitrary data in an interface a machine can understand.

Labels, like people, aren’t always perfect
In traditional, supervised machine learning, large numbers of positively labeled examples are required to train a model on a specific task such as classification or entity extraction. This requirement has been addressed by an ever-evolving ecosystem of workflow tools that aim to provide an interface between a human’s caloric-compute to distill some relevant knowledge to apply to data and a model to then learn that concept.
Let’s take a look at this evolution of the labeling landscape.
Gen0 - You + Spreadsheets

Midjourney - hit or miss on human anatomy
A toolchain that many a grad student is intimately familiar with. The tools are ubiquitous and easy enough to use…but come at the expense of scalability, validation, and transparency. I am still convinced that the most used software for labeling data, even today, are Microsoft’s Excel and Google Sheets.
Benefits
- Free tools
- No training required
- It does the job
Drawbacks
- Non-scalable effort required
- Manual validation
- No labeling “sugar,” e.g., annotator agreement, error analysis, etc.
Gen1 - The Managed Workforce Figure Eight/Appen/Crowdflower

The demand for inexpensive labels gave rise to the managed and often outsourced workforce to service labeling tasks that require little to no domain expertise (image segmentation, transcription, bounding boxes, sentiment, etc.). Companies hired and managed outsourced teams in low-cost labor markets such as the Philippines, Bangladesh, and India to deliver the lowest cost-per-label possible.
Benefits
- 24/7 worldwide workforce
- Rapid time-to-label
- Project management/consulting for labeling workloads
Drawbacks
- Cost quickly spiral out of control when scaled or provided on a continuous basis
- Lack of domain expertise of labelers
- Security/Compliance concerns - Sending data to a 3rd party, let alone a distributed workforce in a foreign country is a non-starter for sensitive data
Gen2 - Manage YOUR Workforce - LabelBox, Label Studio, Scale AI
Driven by the above constraints, a number of tools evolved to help manage your workforce. Instead of dollars-in, labels-out with fully managed workforces, these software tools enabled companies to securely label their own data, while providing the administrative and workforce management tooling necessary for internal teams.
These tools can be installed on-premise and provide a way to securely create labels manually at a fixed software cost, with variable labor costs defined by the annotators
Benefits
- Secure deployments
- Workforce Management tooling makes management easier
- Domain-specific tasks
Drawbacks
- Labeling is a difficult and monotonous task
- OpEx and Administrative overhead of hiring, training, and managing annotation teams with high turnover
- Expensive subject-matter-experts are still expensive labor when needing to scale labels
Gen3 - AI-Assisted Automation - Watchful, Snorkel, Prodigy, etc.

The pain of labeling, combined with the ever-growing need for more labels faster, led to tools (including our own!) that bring automation to knowledge distillation in addition to guided error analysis. This generation of tools leverages approaches like active learning, transfer learning, and weak supervision that enable data scientists and SMEs the ability to rapidly and reliably label with features that help scale manual effort, resulting in 10-100x efficiency gains from traditional labeling. In addition, many of the tools in this generation have programmatic interfaces, bringing automation and scale never possible before.
The goal for this generation is efficiency. Calories per label. How do we minimize the amount of human effort to correctly apply labels repeatably, programmatically, and scalably. This power doesn’t come without some sacrifice
Benefits
- 10-100x efficiency gains over legacy labeling solutions/services
- Programmatic access and integration into MLOps pipelines
- Data-as-code for audibility, interpretability, and repeatability of domain knowledge
Drawbacks
- Tradeoffs in explainability with model-based labeling
In each of these evolutions, there is an assumption (less so in Gen3) that the labels and class space to apply to data comes from humans. Technology was built and adapted under that assumption to make that process as efficient as possible.
So…what has changed?
Large Language Models (LLM’s). For the first time, we shifted the economics of knowledge. Given the breakneck pace of innovation, these models are only going to improve in performance, cost, and latency of delivery.
This should terrify any legacy labeling solution…and inspire any team assessing tools and resource requirements for language-related tasks.
The Rise of Transformers
](../img/the_transformer_flow.webp)
Source: https://arxiv.org/abs/1706.03762
While not necessarily a “new” technology by today’s pace of innovation, the seminal paper “Attention Is All You Need” was published in 2017. The first wave of transformer-based models, such as BERT, were widely adopted due to their versatility in adapting to new tasks and strong performance in benchmark NLP tasks.
This launched an AI arms race for model size and superiority. The next milestone leap in performance was with the release of OpenAI’s GPT-3 (and subsequently 3.5/4), the model that powers ChatGPT, with 175 billion parameters and a training set consisting of over 300 billion tokens, representing a very significant portion of the natural language surface area of the entire internet. For context BERT, depending on the flavor, has 110 - 340 million parameters…and the performance difference for general NLP tasks is…staggering.
Key improvements of GPT over earlier transformer architectures like BERT:
- Text Generation: GPT is designed as an autoregressive model, meaning it generates sequences based on the previous context. This makes GPT more suitable for generating coherent and fluent paragraphs of text, something that BERT is not explicitly designed to do.
- Few-Shot Learning: Starting from GPT-3, these models have shown impressive few-shot learning capabilities. Given a few examples of a task at inference time, they can often perform the task quite well. This differs from BERT, which typically requires task-specific fine-tuning to perform a new task.
- Scaling: GPT-3 and GPT-4 have demonstrated that as the model size increases (both in terms of the number of layers and the total number of parameters), the performance on a variety of tasks improves. GPT-4, with its hundreds of billions of parameters, is a testament to the success of this "scale-up" approach.
- Training Corpus: GPT-3/4 models were trained on a more diverse and larger corpus, which might give them an edge in understanding and generating a wider range of language patterns and knowledge.
- Simplicity of Use: Once a GPT model is trained, you can use it directly to generate text without the need for additional task-specific fine-tuning. You can provide a task description and some examples directly in the prompt, and the model will try to perform the task. This makes GPT models more straightforward to use for many tasks.
Model improvements aside, the major catalyst to the current NLP Renaissance and GenAI VC feeding frenzy was the interface that OpenAI chose to release in the world, chat. The release of ChatGPT provided the first AI experience that looked and smelled like the AI we have been promised for decades. We now have a nearly universal interface enabling nearly anyone to experience and wield the result of billions of dollars in research efforts and compute.
While not always perfect…
Source: ChatGPT
Source: ChatGPT
It can be impressive

Source: ChatGPT
But more importantly, it has given non-technical users a perspective on both the amazing potential and sometimes harsh realities and limitations of AI today. Many of our customers have reported that one of the biggest shifts internally has been the expectations of product managers and business stakeholders of the “art of the possible” and has shifted performance expectations to where “good enough” is often “fantastic” for a variety of generative and low-stakes predictive applications.
So…what? What does this have to do with Data Labeling “dying?”
LLM’s as Labelers
Well, for starters…these models are already proving to be pretty good at labeling, depending on the task.
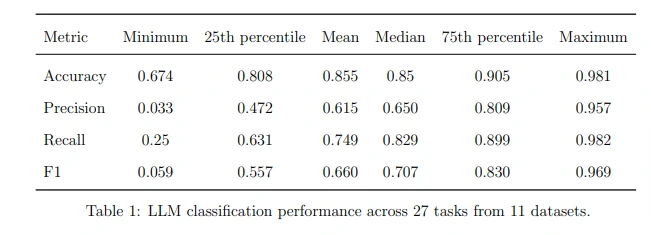
https://arxiv.org/pdf/2306.00176.pdf
While performance was highly task dependent in the above study…these are still early days in terms of performance, let alone cost and latency, all of which I expect to improve dramatically as an incredible amount of intellectual and actual capital continues to be invested in both enterprises and the open source community.
In the paper above, they were able to annotate over 200,000 text samples using GPT-4 across 27 tasks, done for the princely sum of $420 USD. This includes seven iterations on the datasets to measure consistency. That is 1.4 million labels at a cost of $0.0003 per label. I think we can safely assume that no managed service nor in-house annotation pipeline would be able to match.
Synthetic Data Made Easy
Not only are they able to perform surprisingly well as zero-shot learners, but they can also generate synthetic examples and, in some cases, obviating the need for labeling data at all. This is particularly impactful in applications where there are significant privacy and/or regulatory concerns around data access (e.g. finance, legal, healthcare)

https://arxiv.org/pdf/2303.04360.pdf
Learning In Context
LLM’s ability to generalize to new tasks is impressive to say the least. Instead of 10-20k labeled examples, rounds of validation, and then training a model, LLM’s are able to take advantage of their massive training corpus and statistical understanding of language and “learn” a new task when just given one or a few number of examples, called one-shot or few-shot learning.
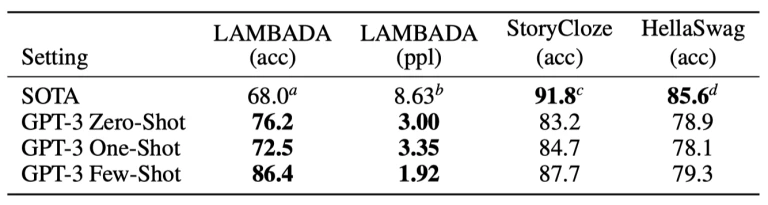
https://arxiv.org/pdf/2005.14165.pdf
Transformers have ultimately shifted the caloric economics of knowledge retrieval and application, the very domain that data labeling services and tools have grown to address. We can now scale *********knowledge…*********what does that change for model and AI application development? What does that mean for the companies built on a now questionable premise that labeling is a human-bound problem?
Evolve or Die
Without significant innovation (in technology and/or business model), Gen1 companies will die. Scale.ai is a perfect example of a Gen1 company poised for success. While starting with the managed workforce model, they have consistently been improving their software offering and recently announced their Generative AI and data prep/management platform. Winners will be defined by those that invest heavily into developing tooling that leverages data for better model development rather than a labeling-centric solution.
Source: TradingView
Gen2 and 3 are where we will see and are seeing the most innovation, with incumbents rapidly adopting ML-assisted labeling functionality, integrations to LLM providers, and GenAI-specific workflow features (RLHF, safety, alignment, data generation, etc.). This makes sense, as these companies (mine included!) were built on the value prop of minimizing manual effort and maximizing automation.
Many of these companies have long embraced the concept of data-centric model development, originally coined by Andrew Ng, which is defined by dedicating effort to iterate on better data - which is far cheaper and easier than the alternative - iterating on the model. This methodology has gained a lot of traction, MIT even offers a course! This shift will change “labeling” as we know it today, and will instead be consumed as a function data prep, exploration, and enrichment.

If AI = Code + Data, where the code is a model, then the LLM revolution has confirmed the long-whispered (and sometimes shouted) prophecy that models will become commodified and the real value will be in the data. Identifying the best examples for fine-tuning, engineering for data quality, and validating the results of ever-increasingly more powerful models will become the norm. Humans give feedback and direction, the machines learn, and guide the human to potential errors resulting in more performant systems over time.
What about Gen0? Excel/Sheets? Like the noble cockroach, these will outlive us all. But even these tools are evolving. While not labeling specific, both Microsoft and Google are integrating LLM’s into their offerings. Prior to the first class integrations, we even saw GPT for Sheets, a plugin with over 2M installs.

What Are We Doing At Watchful?
I must not fear. Fear is the mind-killer. Fear is the little-death that brings total obliteration. I will face my fear. I will permit it to pass over me and through me. And when it has gone past I will turn the inner eye to see its path. Where the fear has gone there will be nothing. Only I will remain.
- Bene Gesserit Litany Against Fear, Frank Herbert’s Dune

So, where does a once-in-a-generation technology shift leave us at Watchful? Well, for starters, it leaves us with a great deal of respect for the companies and individuals working on developing and improving foundation models…and a healthy urgency of the need to innovate and continue to deliver value for our customers in a rapidly changing landscape.
Data Labeling to Machine Teaching
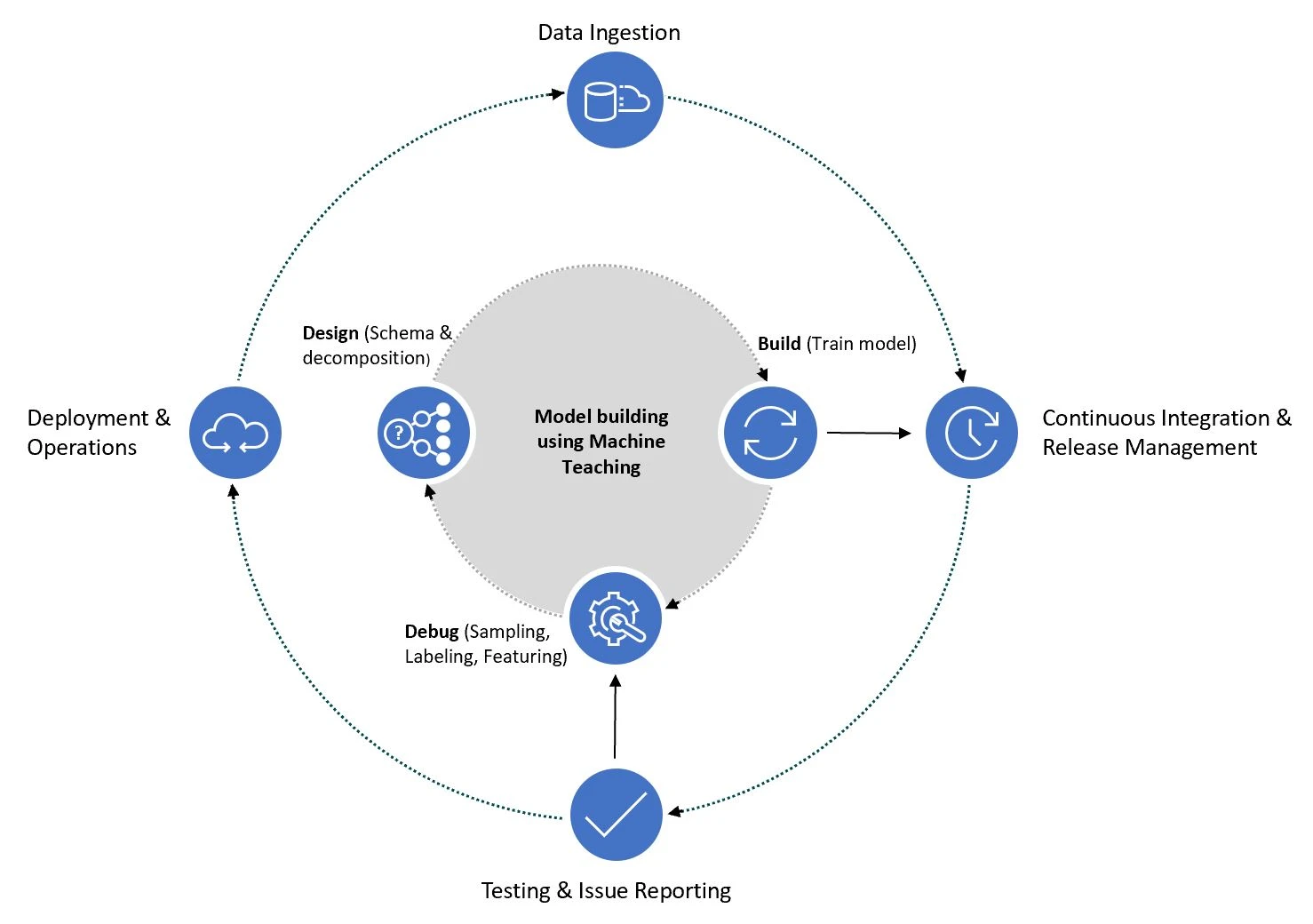
We are embracing the evolution from a point-solution tool focused on labeling data, to a more holistic experience called Machine Teaching. Originally coined by Microsoft, where the goal is not “just” labeling data, but instead provides a student-teacher experience in which the model and user interact, guiding each other to a better result and correcting errors along the way.
If you want to know more about Machine Teaching, check out this article written by my co-founder - A Gentle Introduction to Machine Teaching
More Concretely:
- Continue to build and improve the programmatic labeling experience
- Leverage LLM’s and the power of embeddings for more holistic and powerful data exploration and topic modeling
- Prompt based enrichment/labeling with one or multiple prompts via ensembling
- Prompt engineering, management, and analysis
- Synthetic data generation and augmentation for more robust and complete training datasets
- First-class fine-tuning interfaces and validation for model-based enrichment and labeling
We are focused on continuing to improve on the transformational programmatic labeling workflow used in production at our customers ranging from the Fortune 50 to solo employee startups and practitioners. We will leverage LLMs for a variety of knowledge distillation/extraction tasks as well as continue to build a toolchain for the modern data-centric model development workflow.
Stay tuned as we are about to announce our first integration with LLM’s - using one or multiple prompts to enrich, classify, and extract unstructured text. Combine these prompt-based labels with other sources of supervision and signal to reliably embed LLM functionality for discriminative tasks.
Wrapping Up
We are in the middle of a paradigm shift of how we manage, distill, and apply knowledge…which is exciting. There is a break-neck pace of innovation and a level of hope/enthusiasm/excitement that I feel has been missing in tech since the pandemic.
As with any major shift, incumbent/legacy solution providers will only survive through innovation…and more specifically velocity of innovation. New companies with new ideas are coming to market everyday (varying wildly in quality mind you), unburdened and untainted with the constraints of legacy annotation and model development.
We, at Watchful, are as excited as anyone about this tectonic shift happening in NLP, and embrace it. We are still holding strong to building the next generation of machine teachers, enabling more individuals and organizations to build meaningful AI.